 |
|
 |
|
|
|
En el capitulo anterior vimos el funcionamiento de la interfase de comandos Bash y comenzamos viendo el poder que posee Unix para el manejo de la información.
En este capitulo trataremos temas un poco más específicos, concentrándonos en los aspectos más importantes que podremos ver en nuestro sistema operativo.
El hecho de que estas terminologías empleadas en GNU/Linux, antes se hayan aplicado a Unix, hacen que él saberlas nos abra las puertas a todo un sinfín de particularidades compartidas que hacen mucho más versátil el trabajo con cualquier entorno que sea equivalente.6.1: Plomería en GNU/Linux
6.1.1: Entrada y salida estándar
Hablamos antes de los 3 archivos que el sistema abría en memoria al iniciarse, estos eran el stdin, el stdout y stderr.
El interprete de comandos configurara estos archivos para que apunten al teclado, en el caso del stdin, y al monitor, en el caso del stdout y stderr.
Existen numerosos comandos de Unix que utilizan la entrada estándar para tomar sus datos y la salida estándar para volcarlos a la pantalla.
La configuración esta dada de este modo ya que el shell espera que se ingresen los datos por el teclado y que su resultado o algún error se reflejen en la pantalla.
Un ejemplo seria el caso del comando cat.
Si usáramos el comando cat, sin ningún argumento, todo lo que ingresáramos se vería repetido en la pantalla.[sebas@LUSI]$ cat
Hola #1 Primera línea escrita por nosotros
Hola #2 Línea devuelta a la salida estándar
Que tal #Ídem 1
Que tal #Ídem 2La entrada se termina presionando |Ctrl. D| que es el carácter de EOT (end of text) fin de texto.
6.1.2 Canalización y redirección:
Existe la posibilidad de desviar la salida o la entrada a un comando para poder realizar funciones complejas u obtener los datos que saldrían por la pantalla directamente a otro archivo.
Lo primero se denomina canalización y lo segundo redirección.
El símbolo que se utiliza para efectuar la canalización es el denominado "pipe" o símbolo de canalización (|).
Este símbolo permite que se pase la salida de una comando o programa a la entrada de otro.
Un ejemplo clásico de la utilización de este símbolo es cuando se requiere listar un directorio que ocupa mas de una pantalla. Se podrá entonces utilizar el comando clásico para listar "ls" y enviar su salida a otro programa que lo muestre de a una pagina de pantalla por ves, por ejemplo el "more".[sebas@LUSI]$ ls -l | more
Esto servirá para realizar lo antedicho ya que la salida del comando "ls" será canalizada para que sea la entrada del comando "more" y este se encargara de mostrar los datos por pantalla.
Lo que se esta utilizando es la canalización de la entrada estándar y la salida estándar.
La salida estándar del comando "ls" es redireccionada hacia la entrada estándar del comando "more" que es cambiada para que también apunte a la canalización.Otros dos símbolos utilizados son el "<" y el ">", que lo que harán será redirigir tanto la salida como la entrada estándar.
Por ejemplo, supongamos que necesitamos guardar en un archivo llamado "listado" la salida del comando "ls".[sebas@LUSI]$ ls > listado
Con esto le indicamos al comando "ls" que redireccione la salida estándar hacia un archivo de nombre "listado". En caso de que el archivo exista, será reemplazado con la nueva información.
Para agregar contenido a un archivo, inmediatamente después del contenido que posea, se tendrá que poner el símbolo de redirección dos veces:[sebas@LUSI]$ ls >> listado
El uso de "<" es para redireccionar el contenido de un archivo hacia la entrada estándar de un comando o programa.
Supongamos que necesitamos ordenar el contenido de un archivo en orden alfabético, lo que lograremos con el comando "sort". Podremos entonces redireccionar el contenido del archivo a la entrada del comando "sort" para que este lo ordene.[sebas@LUSI]$ sort < nombres
De esta manera saldría por pantalla la lista de nombres ordenadas alfabéticamente.
De esta forma también se podrá redireccionar el error estándar para que no salga en pantalla.
Supongamos que quisieran realizar un listado del directorio bin y que si existiese un error lo guardáramos en un archivo:[sebas@LUSI]$ ls /bin 2>/tmp/error.ls
Esta simple redirección solo tendría efecto sobre el error estándar (stderr) o como también se denomina, "descriptor de archivo Nº 2.
Con esta redirección los posibles errores serian redirigidos a un archivo alojado en el subdirectorio /tmp llamado error.ls.
Si quisiéramos dividir tanto la salida por pantalla como el error en dos archivos separados podríamos realizar algo como esto:[sebas@LUSI]$ ls /bin 1>/tmp/salida 2>/tmp/error.ls
La redirección y la canalización pueden combinarse para hacer cosas un poco más complejas o realizar tareas en un solo paso.
Supongamos que necesitábamos obtener las 10 primeras líneas del listado que anteriormente guardamos del directorio /bin. Para esto podríamos usar el comando "head" directamente para que obtenga las 10 primeras líneas del archivo listado, pero para entender el uso combinado de la canalización y la redirección lo aremos de otra forma.[sebas@LUSI]$ sort < listado | head
Como se puede ver, se a pasado por medio de una redirección el contenido del archivo "listado" al comando "sort" y por medio de la canalización hemos pasado la salida estándar del comando "sort" al comando "head".
6.2 Permisos de archivos, sus dueños y grupos
Para entender mejor el concepto de permisos se tendrá que tener en cuenta que cada usuario puede pertenecer a uno o más grupos. Cada usuario pertenece por lo menos a un grupo, que es establecido en el momento en que el usuario se crea.
El administrador del sistema puede agregar al usuario a otros grupos.
Estos grupos son necesarios para poder establecer una política de acceso mas organizada dado que en cualquier momento se podría dar a un archivo determinado el acceso a personas de un grupo determinado lo único que se tendría que hacer s agregar a los usuarios que se quieran dar permisos a ese grupo.
Para cada objeto (archivo) que se encuentre en el sistema, GNU/Linux guarda información administrativa en la tabla de inodos, tema que abarcaremos en mayor detalle mas adelante.
Entre los datos que se guardan en esta tabla se encuentran la fecha de creación del archivo, modificación del archivo y la fecha en que se cambio el inodo.
Pero además contiene los datos en los que se centra toda la seguridad en UNIX. Estos son:· El dueño de archivo
· El grupo del archivo
· Los bit's de modo o también llamados permisos de archivo.
En este tramo nos centraremos en primer medida en entender los permisos y en establecer la forma en que pueden trabajar con ellos.6.2.1 Conceptos
Al ser UNIX y GNU/Linux sistemas operativos multiusuario, para que se puedan proteger los archivos se estableció un mecanismo por el cual se le pueden otorgar permisos a un determinado usuario o grupo.
Esto permite, por ejemplo, que si existe un archivo creado por un usuario en particular, este será propiedad del usuario y también tendrá el grupo del usuario.
Se permite que los archivos sean compartidos entre usuarios y grupos de usuarios.
Por ejemplo si sebas quisiera podría prohibir el accesos a un archivo determinado que le pertenezca a todos los usuarios que no pertenezcan a su grupo de usuarios.Los permisos están divididos en tres tipos: Lectura, escritura y ejecución (rwx). Estos permisos pueden estar fijados para tres clases de usuario: el propietario del archivo, el grupo al que pertenece el archivo y para todo el resto de los usuarios.
El permiso de lectura permite a un usuario leer el contenido del archivo o en el caso de que el archivo sea un directorio, la posibilidad de ver el contenido del mismo. El permiso e escritura permite al usuario modificar y escribir el archivo y en el caso de un directorio permite la crear nuevos archivos en él o borrar archivos existentes. El permiso de ejecución permite al usuario ejecutar el archivo, si tiene algo par ejecutarse. Para los directorios permite al usuario cambiarse a él con el comando "cd"
6.2.2 Como se interpretan los permisosPara poder interpretar los permisos de archivos nada mejor que utilizar el comando "ls -la"
Para ver un listado largo de un directorio e ir viendo cada uno de ellos.[sebas@LUSI]$ ls -la
total 13
drwxr-sr-x 2 sebas user 1024 May 2 09:04 .
drwxrwsr-x 4 root staff 1024 Apr 17 21:08 ..
-rw------- 1 sebas user 2541 May 2 22:04 .bash_history
-rw-r--r-- 1 sebas user 164 Apr 23 14:57 .bash_profile
-rw-r--r-- 1 sebas user 55 Apr 23 14:44 .bashrc
-rwxrwxr-x 1 sebas user 0 Apr 14 19:29 a.out
-rwxrwxr-x 1 sebas user 40 Apr 30 12:14 hello.pl
-r-------- 1 sebas user 64 Apr 29 14:04 hola
-rwxrw-r-- 1 sebas user 337 Apr 29 13:57 lista
-rw-rw-r-- 1 sebas user 40 Apr 30 12:31 listador
-rw-rw-r-- 1 sebas user 0 May 2 09:04 null
-rwxrwxr-x 1 sebas user 175 Apr 30 12:30 prue.pl
-rwxrwxr-x 1 sebas user 56 Apr 23 15:08 que.sh
Como se puede apreciar en este listado, también están el directorio actual, representado por un punto "." y el directorio padre representado por dos puntos "..". Ellos también poseen permisos y atributos que son mostrados.
Para ir entendiendo un poco mas vamos a explicar que significan los primeros 10 dígitos.
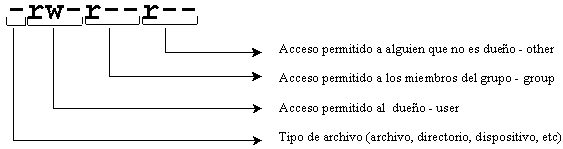
Veamos unas tablas que nos esclarecerán un poco mas que significa cada uno de estos caracteres.
Primero que todo veremos aquellos caracteres que podrían aparece en el primer bit que en el ejemplo anterior podemos ver que es un solo guión, esto nos indica que es un archivo común.
La tabla siguiente explica el significado del primer símbolo de acuerdo al tipo de archivo:

Los siguientes 9 símbolos se toman en grupos de tres y cada grupo pertenece a una clase de permisos, y se muestran a continuación:

-rwxrw-r-- 1 sebas user 337 Apr 29 13:57 lista
De esta forma podremos interpretar el listado generado a partir de "ls -l" de mejor manera.
El primer símbolo nos esta indicando que el archivo es un archivo común.
El primer grupo de tres símbolos representa los permisos para el dueño del archivo (owner) que en este caso posee permisos de lectura, escritura y ejecución.
El segundo grupo de tres símbolos representa los permisos para el grupo al cual pertenece el archivo (group), que en este caso tienen permisos de lectura y escritura.
El tercer grupo de tres símbolos representa los permisos para todo el resto de los usuarios (other) en este caso es solo de lectura.
El numero que sigue (1) representa el numero de nombres que el archivo posee. Esto representa la cantidad de enlaces que existen a este archivo y lo veremos mas adelante cuando tratemos el tema de enlaces simbólicos y duros.
A continuación esta el nombre del dueño del archivo y del grupo al cual pertenece el archivo.
El "337" representa el tamaño del archivo expresado en bytes.
Lo siguiente es la fecha y hora de modificación del archivo e inmediatamente después esta el nombre del mismo.6.2.3 Dependencias
Los permisos de los archivos también dependen del directorio donde estén guardados. En un ejemplo común podríamos dar el caso de un archivo que posea todos los permiso, tanto para el usuario, grupo y otros pero no se podrá acceder a el si no se cuenta con permisos de lectura y ejecución en el directorio que los contiene.
Esto funciona en el caso que se quiera restringir el acceso a un directorio determinado y a todos los archivos que este contiene. En lugar de cambiar los permisos uno por uno solo tenemos que sacarle los permisos necesarios para que se prohíba el acceso mismo al directorio y con esto, y aunque se disponga de todos los permisos en los archivos contenidos en este directorio, no podrán ingresar para usarlos.
Esto también esta dado para toda la ruta del archivo. Es decir que no-solo el ultimo directorio, el cual lo contiene, tiene que tener los permisos necesarios, sino que todos los directorios que lo preceden también.6.2.4 Cambiando permisos
En él capitulo 4 vimos la utilización del comando "chmod", pero en este entraremos a explicar en mejor forma su utilización. Además trataremos el tema de otro tipo representación de permisos posibles, la representación octal, que extremadamente útil a la hora de establecer nuevos permisos.
El comando chmod se emplea utilizando símbolos como a,u,g,o que representan a todos (a "all")al usuario (u) al grupo (g) y a todos los demás (o).
Existen símbolos para agregar (+) quitar (-) o dejar invariantes loa permisos (=).
Además se tendrán que usar los símbolos característicos para cada tipo de permiso. Para el permiso de lectura (r), para el permiso de escritura (w) y para el permiso de ejecución (x).
Solo el dueño del archivo puede cambiarlo con él; excepción del root que también lo puede hacer.
Para ejemplificar un cambio de permisos usaremos el archivo "lista".[sebas@LUSI]$ ls -l lista
total 1
-rwxrw-r-- 1 sebas user 337 Apr 29 13:57 lista[sebas@LUSI]$ chmod a-r lista
[sebas@LUSI]$ ls -l lista
total 1
--wx-w---- 1 sebas user 337 Apr 29 13:57 listaDe esta forma se le han sacado todos a todos los grupos los permisos de lectura.
Algunos ejemplos más.[sebas@LUSI]$ chmod u+r lista
[sebas@LUSI]$ ls -l lista
total 1
-rwx-w---- 1 sebas user 337 Apr 29 13:57 lista
[sebas@LUSI]$ chmod o+w lista
[sebas@LUSI]$ ls -l lista
total 1
-rwx-w-w-- 1 sebas user 337 Apr 29 13:57 lista
[sebas@LUSI]$ chmod og-w lista
[sebas@LUSI]$ ls -l lista
total 1
-rwx------ 1 sebas user 337 Apr 29 13:57 lista
Ahora bien esta es la forma simbólica pero existe una forma un poco mas sistemática que es la forma de representación octal.
El comando chmod permite establecer los permisos de un archivo por medio de un numero octal de dígitos.
Comúnmente nosotros usamos para contar una representación decimal (0,1,2,3,4,5,6,7,8,9) pero en una representación octal solo se usan 8 números (0,1,2,3,4,5,6,7).
Para establecer el permiso habrá que sumar los dígitos octales de acuerdo a una tabla que se dará a continuación.
Dado que no se realiza acarreo, la suma será común.

Para dar un ejemplo de la suma que se tendrá que realizar, tomemos un archivo con los permisos expresados en forma simbólica y realicemos la conversión.
Ej para representar "-rwxr-w---":

De esta forma si lo que quisiéramos es cambiar los permisos de un archivo, solo se tendría que efectuar la suma necesaria y establecerlo con el comando chmod.
Como ejemplo si se quisiera cambiar los permisos para que el dueño tenga permisos de lectura y escritura y que el grupo y otros solo tengan permisos de lectura, la sintaxis seria:[sebas@LUSI]$ chmod 0644 lista
[sebas@LUSI]$ ls -l lista
total 1
-rw-r--r-- 1 sebas user 337 Apr 29 13:57 listaCon la practica se sabrán cuales son las sumas mas utilizadas y podrán ver que es mucho más sencillo el establecer de esta forma los permisos de archivos.
Lo que nos quedaría ver es el caso en que se quisiera cambiar el usuario o el grupo del archivo.
Para esto se usa el comando "chown" y su sintaxis es similar a la de chmod pero con la variante que se dan los nombres de los usuarios y del grupo.
Por ejemplo, supongamos que quisiéramos cambiar el nombre de usuario del archivo lista.
A diferencia que con los cambios de permisos tendremos que ser el root.
[root@LUSI]# ls -l lista
total 1
-rw-r--r-- 1 sebas user 337 Apr 29 13:57 lista[root@LUSI]# chown nanci lista
[root@LUSI]# ls -l lista
total 1
-rw-r--r-- 1 nanci user 337 Apr 29 13:57 listaSi se quisiera cambiar también el nombre del grupo, se tendría que poner un punto entre el nombre de usuario y el grupo:
[root@LUSI]# ls -l lista
total 1
-rw-r--r-- 1 sebas user 337 Apr 29 13:57 lista[root@LUSI]# chown nanci.ventas lista
[root@LUSI]# ls -l lista
total 1
-rw-r--r-- 1 nanci ventas 337 Apr 29 13:57 listaPor supuesto que tanto el usuario como el grupo al que se hacen referencia tendrán que existir en el sistema, sino saldrá un error.
En el caso que solo se quiera cambiar el grupo y no el usuario, se tendrá que poner un punto delante del nombre del grupo, omitiendo poner el nombre del algún usuario. O si se quiere, se podrá poner el nombre de usuario que estaba anteriormente.
[root@LUSI]# ls -l lista
total 1
-rw-r--r-- 1 sebas user 337 Apr 29 13:57 lista[root@LUSI]# chown .ventas lista
[root@LUSI]# ls -l lista
total 1
-rw-r--r-- 1 sebas ventas 337 Apr 29 13:57 lista
6.2.5 Puntos adicionales
Explicaremos algunos puntos sobre permisos que son de gran utilidad para la seguridad de nuestro sistema.
umask: Esta es la abreviatura de "user file-creation mode mask" o "mascara del modo de creación de archivos de usuario" y es un numero octal de cuatro dígitos que se utilizan para fijar los permisos de los archivos recién creado.
Esto puede ocasionar confusión pero en realidad es una utilidad que permite el uso del sistema por múltiples usuarios sin que peligre la privacidad.
En la mayoría de los UNIX los archivos que son creados por el usuario poseen permisos 0666 que dan permiso de lectura y escritura a cualquier usuario. En relación con los programas, estos se levantan con 0777 donde cualquier usuario puede leer, escribir y ejecutar el programa.
Normalmente el administrador del sistema aplica una "mascara" al usuario en el archivo .bash_profile y esta es usada para la creación de archivos haciendo una operación simple "AND" bit por bit con el complemento del valor umask bit por bit.
La función umask esta integrada al interprete de comandos.
Para ejemplificar el proceso tomemos un archivo creado por el usuario.

El modo resultante es que el dueño tiene permisos de lectura y escritura y los demás y el grupo solo de lectura.

El modo resultante es que el dueño tiene permisos de lectura y escritura y los demás y el grupo no tienen ningún permiso.
Una forma de darse cuenta de la forma en que funciona el umask es tener en cuenta que el valor (2) inhabilita el permiso de escritura mientras que el valor (7) inhabilita los permisos de lectura escritura y ejecución.
A continuación daremos una tabla con los valore comúnmente usados para el umask.

SUID y SGID:
Existen ocasiones que los usuarios necesitan ejecutar algún programa que requiere de privilegios. Un ejemplo de esto es el uso del programa passwd para cambiar la contraseña.
Seria un error darle a los usuarios los privilegios necesarios para que puedan ejecutar esta clase de programas ya que el usuario podría cambiarse de grupo o crear una cuenta con privilegios de root.
Para que esto no suceda se implemento en UNIX un sistema por el cual un programa que cuente con SUID o SGID puede ser ejecutado con los privilegios del dueño y/o grupo del programa.
Para que quede mas claro se tiene que saber que cada usuario esta identificado por el sistema con un numero de identificación tanto para el, como para el grupo. Este numero se denomina UID (user ID) para el caso de los usuarios y GID para el caso de los grupos.
Por ejemplo, un usuario podría tener un UID 100 y un GID 500. EN el caso del root, este tiene UID 0 y GID 0. Mas adelante se vera esto en mayor detalle.
Lo que se efectúa con el sistema SUID es una adquisición temporal de un UID o GID distinto al propio cuando se esta ejecutando el programa.
Cuando un programa cambia de UID se denomina SUID (set-UID:se establece UID) y cuando cambia de GID se denomina SGID (set-GID:se establece GID) Un programa puede ser SUID y SGUID al mismo tiempo.
Para darse cuenta si un programa es SUID o SUI basta con hacer un listado largo con el comando "ls -l" y se vera que donde tendría que estar una "x", que asigna permisos de ejecución, va a estar una letra "s".Ej:
[sebas@LUSI]$ ls -l /usr/bin/passwd
-rwsr-xr-x 1 root root 28896 Jul 17 1998 /usr/bin/passwd
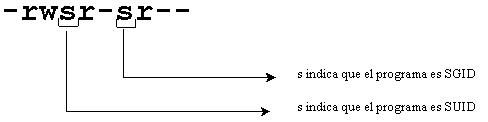
BIT adhesivo:
El los antiguos sistemas UNIX la memoria era algo esencial y escasa dado su costo.
Para poder aprovechar mas esta se empleo una tecnología que mantenía parte de programas esenciales en el área swap de memoria para que pedieran ser usados mas rápidamente dado que si se tendrían que ir a buscar al disco se tardaría mas. Estos programas se los marcaba con un BIT especial, un BIT adhesivo o "sticky BIT" y estos archivos así marcas eran los que valía la pena mantener ya que esas partes del programa que se guardaban en memoria también podían ser usadas por otros.6.3 Enlaces de Archivos
En ocasiones es necesario dar a un mismo archivo distintos nombres o, y esto dado para mantener la integridad de los datos, se hace necesario que un mismo archivo que va a ser modificado por varias personas pueda estar representado por un nombre distinto.
Dada la representación que GNU/Linux le da a los archivos es posible que dos o mas nombres apunten al mismo contenido en el disco rígido.
Recordemos que los archivos se representan por el numero de inodo en el disco y es el único identificador que el sistema tiene del archivo. Si se quiere ver el inodo que representa un archivo basta solo con agregar el modificador "-i" al comando "ls".(ls -i).
Existen dos tipos de enlaces. Los duros y los simbólicos.6.3.1 Enlaces duros o "hard links"
Para crear enlaces entre los archivos se utiliza el comando "ln". Para dar un ejemplo, si se quisiera hacer un enlace del archivo "hola" el comando seria.
[sebas@LUSI]$ ln hola saludo
Con esto y si hacemos un listado mostrando los inodos nos daremos cuenta de varia cosas:
[sebas@LUSI]$ ls -il
total 214438 -r-------- 2 sebas sebas 64 Apr 29 14:04 hola
14438 -r-------- 2 sebas sebas 64 Apr 29 14:04 saludoComo se ve el numero de nombres que los archivos tienen ahora es "2" dado que hemos creado otro nombre que es un enlace al contenido que tenia el archivo "hola" en el disco. Esto puede verse dado que el primer numero del listado, "14438", es el numero del inodo donde comienza el contenido del archivo "hola".
Aunque parezca que el contenido se a duplicado, esto no es así. Ambos archivos apuntan al mismo sitio.
Por esto, un archivo no se borra hasta que se halla borrado el ultimo de sus nombres.
De esta forma también podeos decir que un directorio no es mas que un archivo que contiene información sobre la translación enlace a inodo. También que cada directorio tiene dos enlaces duros en el: "." (un enlace apuntando a si mismo) y ".." (un enlace apuntando a su directorio padre). En el directorio raiz (/) el enlace ".." siempre apunta a /.6.3.2 Enlaces simbólicos
A diferencia con los enlaces duros, estos enlaces solo dan otro nombre a un archivo pero no hacen un enlace al nivel de inodo. Se puede hacer una comparación con los "Accesos directos" de Windows 95® .
La orden "ln -s" genera un enlace simbólico:
[sebas@LUSI]$ ln -s hola saludos
[sebas@LUSI]$ ls -il
total 2
14438 -r-------- 1 sebas sebas 64 Apr 29 14:04 hola
14446 lrwxrwxrwx 1 sebas sebas 4 May 7 08:33 saludos -> holaComo se ve, el enlace nos muestra a que archivo esta apuntando.
Existen diferencias entre este tipo de enlaces y los duros como que ya no están apuntando al mismo inodo.
Además los bit de permisos aparecen todos encendidos dado que no son usados. Los permisos que se utilizan son los del archivo al que se esta apuntando.
Si no fijamos bien, en la primera posición de los permisos veremos una letra "l", esto nos indica que es un enlace simbólico.
Otra particularidad es que se pueden crear enlaces simbólicos de archivos que no existen; pero lo mismo no es cierto para los enlaces duros. Con los enlaces simbólicos se puede saber a que archivo están apuntando, no así con los duros.
Los enlaces simbólicos son ampliamente usados para las librerías compartidas.
6.4 Tareas y Procesos
En este punto tendremos que empezar a determinar que es un proceso y una tarea.
Anteriormente dijimos que un programa se trasformaba en proceso en el momento en que este se ejecutaba y estaba en memoria.
Además del nombre que el proceso recibe, que es el nombre del programa que esta corriendo, recibe también un numero identificativo llamado PID (process ID, o ID de proceso).
Si ejecutamos el comando "ps" veremos los procesos que están ejecutando en este momento con nuestro UID, es decir que estamos corriendo nosotros mismos:[sebas@LUSI~]$ps
PID TTY STAT TIME COMMAND
172 p0 S 0:00 -bash
184 p0 R 0:00 ps
[sebas@LUSI~]$Se puede ver que están corriendo dos procesos, el bash (que es el interprete de comandos) y el proceso "ps" que es el que estamos usando en este momento en una terminal determinada.
Como se puede ver el primer numero es el PID que el sistema le asigna al proceso y en la columna COMMAND se puede ver el nombre del proceso.
De ninguna manera estos son todos los procesos que se están ejecutando en el sistema. Si se quisieran ver todos los procesos tendrían que poner "ps -ax" con lo que obtendrían un listado con todos los procesos que se estén ejecutando.
Como se puede apreciar, están ambos procesos ejecutándose al mismo tiempo, pero solo uno de ellos esta activo, el comando "ps". Nos podemos dar cuenta de esto ya que en la columna STAT aparece en la línea del bash la letra S de SLEEP, ya que en ese momento el interprete de comandos esta esperando a que el proceso "ps" termine. Y es aquí donde esta la diferencia entre proceso y tarea. Aunque ambos son procesos, una tarea se refiere al proceso que esta corriendo. Este calificativo solo lo da el shell del sistema cuando se utilizan los controles de tareas dado que no todos los interpretes de comandos soportan este tipo de control.6.4.1 Primer y Segundo plano
Cualquier proceso puede estar en primer o segundo plano. Lo único a tener en cuenta es que solo un proceso estará en primer plano al mismo tiempo y es con el que estemos trabajando e interactuando en ese momento.
Un proceso que este en segundo plano no recibirá ninguna señal de parte nuestra, es decir que no nos podemos comunicar con él a través, por ejemplo, del teclado.
La utilidad de enviar un programa a segundo plano esta dada por el hecho de que existen tareas que no requieren de nuestro control para que se ejecuten. Por ejemplo, bajar algún archivo de Internet, compilar el kernel u otro programa. Estas son tareas que pueden ser lanzadas tranquilamente en segundo plano.
Para lanzar un proceso en segundo plano, tendremos que poner delante del comando con un símbolo "&".
Para ejemplificar esto usaremos el comando "find" y dejaremos que busque todos los archivos que existen en el disco:[sebas@LUSI~]$find / -name "*"
Esto nos mostraría una lista interminable de archivos por pantalla y nos quedaríamos sin el control del interprete de comandos mientras esta ejecutándose.
Podríamos usar el dispositivo null, recuerdan que era como un agujero negro donde todo lo que se enviaba a él desaparecía, para redirigir la salida y que no saliera por pantalla.[sebas@LUSI~]$find / -name "*" > /dev/null
Igualmente así no contaríamos con la atención de nuestro interprete de comandos hasta que terminara el trabajo el comando "find".
La forma de tener la atención del shell inmediatamente después de lanzar el proceso "find" es enviándolo en segundo plano.[sebas@LUSI~]$find / -name "*" > /dev/null &
[1] 192
[sebas@LUSI~]$Como se ve regreso de inmediato al shell, pero antes envió un mensaje a la terminal.
El [1] representa a un numero de trabajo que el shell asigna a cada uno que pasa a segundo plano.
Inmediatamente después vemos el numero de PID del proceso. Podremos identificar al proceso por cualquiera de los dos números mientras se encuentre en segundo plano.
Para ver cuantos trabajos están ejecutarse en este momento podemos usar el comando "jobs"[sebas@LUSI~]$jobs
[1]+ Running find / -name "*" >/dev/null &Podremos eliminar un proceso que esta ejecutando con la ayuda del comando "kill" seguido bien sea del numero de trabajo precedido de un signo "%" o del numero de PID.
De esta forma estamos matando al proceso pero puede darse el caso de que este tarde en desaparecer dado que tiene que limpiar el entorno, por esto muchas veces parecerá que no nos a hecho caso. En realidad el proceso esta haciendo una especie de limpieza del sistema evitando así mal funcionamiento del mismo y/o una inconsistencia en los datos con que trabajaba.
Como ejemplo usaremos otro comando muy típico, el comando "yes". Este comando enviara a la salida estándar continuamente la letra "y". Sirve este comando para que en caso de que se requiera contestar afirmativamente a las peticiones de un programa pudiéremos mediante una redirección contestarle con un "y" a cada pregunta.
Si lo ejecutáramos sin redirigir la salida a /dev/null, nos llenaría la pantalla con una columna infinita de "y". Por esto lo enviaremos a segundo plano redirigiendo la salida y luego lo mataremos con el comando "kill".[sebas@LUSI~]$yes > /dev/null &
[1] 201
[sebas@LUSI~]$kill %1
[sebas@LUSI~]$jobs
[1]+ Terminated yes >/dev/null
[sebas@LUSI~]$Como podrán ver, en el momento en que se mando el comando kill, no hubo ningún mensaje. Solo después de ejecutar el comando "jobs" se nos informo que el trabajo numero "1" había finalizado "TERMINATED".
Podemos también hacer lo mismo empleando el numero de PID con lo que obtendremos idénticos resultados.[sebas@LUSI~]$kill 201
6.4.2 Como parar y relanzar tareas.
Los procesos pueden ser suspendidos y dejados parados temporalmente hasta que nosotros dispongamos, para así relanzarlos y que continúen ejecutando donde se habían quedado.
Esto es de gran utilidad. Supónganse que se esta trabajando con el editor de texto "vi" y no queremos trabajar en otra consola, solo tenemos que enviar al programa "vi" a dormir un rato y tendremos el interprete de comandos a nuestra disposición.
En la mayoría de los programas, se envía una señal de terminación utilizando las teclas [ctrl. + c], para poder enviar un trabajo a dormir utilizaremos otra combinación de teclas [ctrl. + z].
Hay que tener en cuenta que no es lo mismo un trabajo en segundo plano que uno que es enviado a dormir.
Un trabajo en segundo plano sigue ejecutándose, en cambio uno que se envía a dormir queda esperando en el lugar donde estaba hasta que sea despertado.
Para ejemplificar esto, enviaremos al comando "yes" a segundo plano y luego lo podremos a dormir.[sebas@LUSI~]$yes >/dev/null &
[sebas@LUSI~]$yes >/dev/null
# Presionamos [ctrl + z][2]+ Stopped yes >/dev/null
[sebas@LUSI~]$jobs
[1]- Running yes >/dev/null &
[2]+ Stopped yes >/dev/null[sebas@LUSI~]$
Como pueden ver, el proceso que se envió a segundo plano todavía se esta ejecutando (Running), en cambio la que se mando dormir esta parada esperando que la relancemos (Stopped).
Para ponerlo en primer plano o despertarlo a cualquiera de los dos podemos usar el signo "%" seguido del numero del proceso o bien el comando "fg".[sebas@LUSI~]$%1
yes >/dev/null & # Ahora presionamos [ctrl + z][sebas@LUSI~]$fg %1
yes >/dev/nullPodremos enviar también un comando que esta durmiendo a que ejecute en segundo plano a través del comando "bg":
[sebas@LUSI~]$jobs
[1]- Stopped yes >/dev/null[sebas@LUSI~]$bg %1
[1]+ yes >/dev/null &[sebas@LUSI~]$jobs
[1]+ Running yes >/dev/null &Cabe decir que tanto "fg" como "bg" son comandos internos del interprete de comando. Esto es así porque es el mismo interprete quien hace el control de tareas. Puede darse el caso de que existan interpretes de comandos que no tengan soporte para control de tareas.
6.4.3 Programas de seguimiento (PS y TOP).
Los sistemas GNU/Linux cuentan varios programas para efectuar el seguimiento de los procesos que se están ejecutando en el sistema.
Entre los mas usados en la interfase de texto están los programas "ps" y "top".ps:
Sin ninguna opción dará la lista de procesos que están corriendo desde la terminal donde se ejecuto el "ps"[sebas@LUSI~]$ps
PID TTY STAT TIME COMMAND
208 p0 S 0:02 -bash
225 p0 R 0:00 ps
[sebas@LUSI~]$Las columnas que nos quedan por explicar son TTY y TIME.
TTY identifica la consola donde se esta ejecutando el proceso. En este caso es una terminal remota.
La columna TIME nos indica la cantidad de tiempo total que el proceso a estado ejecutando. Como se puede ver el tiempo es de 2 segundos. Aunque este horas el sistema encendido, el bash pasa su mayor parte del tiempo esperando que se le envié algún comando para ejecutar, mientras tanto esta esperando dormido.
Puede verse en la columna STAT en que estado se encuentra el programa. Por ejemplo, qui vemos que el bash en el momento de ejecutarse el comando "ps" esta dormido "S" y que le proceso "ps" esta activo "R".
Si añadimos la opción "l" tendremos un listado largo del comando "ps". En algunas versiones se usa la opción "l"[sebas@LUSI~]$ ps l
FLAGS UID PID PPID PRI NI SIZE RSS WCHAN STA TTY TIME COMMAND
100 1000 254 253 17 0 1820 1168 11889d S p0 0:00 -bash
100000 1000 260 254 10 0 900 512 0 R p0 0:00 ps lDentro de esta información esta la columna del UID que identifica el dueño del proceso.
El PID del proceso y también el PPID que es el PID del proceso padre. Podemos apreciar que el padre del comando "ps l" es el bash.
NI viene de "nice" es un nivel que se otorga a un proceso para requerir cierto privilegio. En este caso tiene un muy bajo por ende un proceso que tenga un valor mayor tendrá mas tiempo de procesador para trabajar.
SIZE es el tamaño que tiene el proceso.
RSS es la tamaño del proceso que se encuentra residente en la memoria.
WCHAM es el nombre de la función del kernel donde el proceso esta durmiendo. Esta expresado en forma hexadecimal.Otra forma en la que podemos ver el padre de cada proceso es a través del modificador "f".
[sebas@LUSI~]$ ps f
PID TTY STAT TIME COMMAND
254 p0 S 0:00 -bash
268 p0 R 0:00 \_ ps f
[sebas@LUSI~]$Aquí se puede ver que el comando "ps f" depende del bash.
Ahora bién, esto nos esta mostrando una radiografía de los procesos en el momento, pero no nos muesrtra los cambios que se van teniendo, para esto contamos con el programa "top".
top: Nos mostrara en tiempo real la situación de los procesos que se están ejecutando en el sistema, ordenados por defecto según el porcentaje la CPU que estén usando.
Al ejecutarlo se podrá ver otra información adicional, como la cantidad de usuarios que están en el sistema, cuantos procesos están corriendo y de estos cuantos estas activos, cuantos durmiendo, cuantos en proceso de terminar (ZOMBIE) y cuantos finalizados.
Además se podrá ver la cantidad e memoria física total, la cantidad usada y la cantidad libre; así como también se podrá obtener la misma información de la memoria swap.Lo mas importante es que esta información de ira actualizando automáticamente cada tanto tiempo, por defecto 5 segundos, y que podremos ir alterando lo que va mostrando. Por ejemplo podríamos hacer que ordenara los procesos de acuerdo a la cantidad de memoria que esta usando con solo presionar la tecla "M" mayúscula. U ordenarlo de acuerdo al tiempo que hace que están corriendo.
Otra utilidad es que podríamos matar algún proceso con solo presionar la tecla k y luego darle el numero de PID.El listado que nos mostrara contendrá el numero de PID, el usuario que lo esta ejecutando, la prioridad del proceso (PRI), el valor nice (NI), el tamaño del proceso (SIZE), el tamaño total del proceso junto con los datos que maneja (RSS), el tamaño usado por el proceso en la memoria (SHARE), el estado del proceso(STAT), el tamaño de las librerías del proceso (LIB), el porcentaje de CPU ( %CPU) y de memoria (%MEM) así como también el tiempo de ejecución (TIME) y el nombre del proceso (COMMAND).
6.5 Escritura de Scripts de shell
Hemos llegado a un punto donde podemos realizar tareas más complejas a partir de los comandos aprendidos y es aquí donde radica el poder del interprete de comandos bash.-
Como veremos a continuación, el interprete de comandos es un poderoso lenguaje para realizar script que permitan unir varios comandos para realizar una tarea un poco mas compleja (y es el este el poder principal de todo UNIX). El único requisito es tener nociones básicas de programación para poder sacar todo el provecho posible de esta característica del interprete de comandos. En todo caso, con un poco de practica y un buen sentido de la lógica se podrán hacer también script poderosos para desarrollar la tarea que requerimos.Deberemos saber también que con la ayuda solamente de la conjunción de comandos no podremos hacer script verdaderamente interesantes. Por esto se incorporan las "construcciones de shell". Estas son las construcciones "while", "for-in", "if-then-fi" y "case-esac". Existen muchas más pero estas serán las mas útiles para nosotros en estos momentos. Para mayor información sobre otro tipo de construcciones seria mejor revisar las paginas de manual del interprete de comando "bash" (man bash).
Empezaremos viendo un uso sencillo de la construcción "for-in" que tiene la siguiente sintaxis:
for var in word1 word2
do
commandos
donePara poder usar esto, podríamos realizar una lista de directorios que queramos nosotros de una sola vez.
for dir in /bin /etc /lib
do
ls -R $dir
doneEsto hará un listado recursivo 3 veces. La primera vez que pase por el ciclo, la variable $dir tomara el valor "/bin", la segunda será "/etc" y la tercera "/lib.
Podríamos prescindir del par do/done con el uso de llaves "{}"for dir in /bin /etc /lib
{
ls -R $dir
}
Ya hemos visto anteriormente la idea de argumentos en la utilización de comandos y programas; pero deberemos ver como se realiza la codificación de un script para tomar estos argumentos.
Como antes dijimos, los argumentos eran pasados a los programas para que estos lo utilizaran. En la construcción de script veremos lo que se llaman "variables posiciónales" cuyo valor corresponde a la posición del argumento luego del nombre del script.
Supongamos que tenemos un script que toma 3 argumentos. El primero será el nombre de un directorio, el segundo el nombre de un archivo y el tercero es una palabra a buscar.
Este script buscara en todos los archivos del directorio, cuyo nombre incluya el nombre de archivo que le pasamos como argumento, la palabra que también le estamos pasando.
El script se llamara "miscript" y estará compuesto del siguiente código:ls $1 | grep $2 | while read ARCHIVO
do
grep $3 ${1}/${ARCHIVO}
doneLa sintaxis será: miscript directorio nombre_archivo palabra
Aquí tenemos varas cosas para ver. Primero que nada el uso de las variables posiciónales.
Como se podrá apreciar el numero de la variable, que esta precedido por un signo $, indica la posición del argumento cuando el script es llamado. Solamente se podrán usar 9 variables de este tipo sin tener que emplear un pequeño truco de corrimiento que veremos luego, dado que el "0" representa al nombre del script mismo. Es decir que en este caso la variable posicional $0 valdrá "miscript".
Como se puede ver se han utilizado canalizaciones para poner mas de un comando junto.
Al final de la construcción se esta usando una construcción "while". Esta se usa para repetir un ciclo mientras una expresión sea cierta.while ($VARIABLE=valor)
do
commandos
doneEn este caso esta siendo usada al final de una canalización con la instrucción "read ARCHIVO". Es decir, mientras pueda leer el contenido de la variable $ARCHIVO, continuar.
Esta variable $ARCHIVO contiene el resultado de lo que arrojo la canalización del listado con la salvedad de que tenia que contener la palabra que le enviamos como argumento, es así que solo se imprimirán las líneas en las que coincida la palabra a buscar de los archivos que cumplan con los requisitos.Otra cosa a tener en cuenta es una nueva construcción en este script, ${1}/${ARCHIVO}.
Al encerrar un nombre de variable dentro de llaves podemos combinarlas. En este caso forman el nombre del directorio (${1}) y añadimos una "/" como separador del directorio, y seguido e nombre del archivo donde se aplicara el comando "grep" con la palabra a buscar "$3".Podríamos hacer que este script sea un poco mas documentado. Para esto podríamos asignar las variables posiciónales a otras variables para que se pueda entender mejor su uso.
DIRECTORIO=$1
ARCHIVO_BUS=$2
PALABRA=$3ls $DIRECTORIO | grep $ARCHIVO_BUS | while read ARCHIVO
do
grep $PALABRA ${DIRECTRIO}/${ARCHIVO}done
El numero de las variables posiciónales que pueden usarce en un script, como antes dijimos, se encuentra restringido a 10. ¿Qué pasaría si tenemos mas de 9 argumentos?. Es aquí donde tenemos que usar la instrucción "shift". Esta instrucción mueve los argumentos hacia abajo en la lista de parámetros posiciónales. De esta manera podríamos tener una construcción con esta distribución de variables:
DIRECTORIO=$1
shift
ARCHIVO_BUS=$1De esta manera podríamos asignar el valor de la primer variable posicional a la variable DIRECTORIO y luego el siguiente argumento que habíamos dado se tomara otra vez con el nombre de $1.
Esto solo tiene sentido si asignamos las variables posiciónales a otra variable.
Si tuviéramos 10 argumentos, el décimo no estaría disponible. Sin embargo, una vez que hacemos el que las variables se corran de posición este se convertirá en el noveno y se accederá por la variable posicional $9.
Existe una forma también de pasar como argumento a la instrucción "shift" el numero de posiciones que queremos correr. Por lo cual podríamos usar:shift 9
y así se lograra que el décimo argumento sea el parámetro posicional 1.
Lo que ocurre con los anteriores 9 argumento es que desaparecen si no se los asigno a una variable anteriormente.
Podremos cambiar usar un nuevo parámetro que podrá contener mas de un parámetro pasado al script. Este se denomina "$*" y contendrá el resto de los argumentos que se pasen al script luego de que se haya realizado un corrimiento determinado.
Por ejemplo, si quisiera buscar una frase en lugar de una única palabra el script podría ser:DIRECTORIO=$1
ARCHIVO_BUS=$2
shift 2
PALABRAS=$*ls $DIRECTORIO | grep $ARCHIVO_BUS | while read ARCHIVO
do
grep "$PALABRAS" ${DIRECTRIO}/${ARCHIVO}done
Lo que aquí cambio es que luego de haber asignado a variables los parámetros posiciónales 1 y 2 las variables fueron desplazadas dos veces, eliminando los dos primeros argumentos. Luego asignamos los argumentos restantes a la variable PALABRAS.
Para que sea tomado como una cadena, se lo encerró entre comillas para ser pasado al comando grep, si no lo hiciéramos el bash vería nuestra entrada como argumentos individuales para pasar al "grep".Otro parámetro que es de utilidad es el $# que lleva la cuenta de la cantidad de argumentos pasados al script.
De esta forma podríamos realizar un script que identificara si se le están pasando la cantidad de parámetros que realmente necesita y anunciar el error si faltaran estos.
Para ello utilizaremos la construcción if-then-fi que es muy parecida a la while-do-done, en donde el par if-fi marca el final de un bloque.
La diferencia entre estas construcciones es que el if solo evaluara una vez la condición.
La sintaxis es la siguiente:if [ condición ]
then
hacer_algo
fiLas condiciones que puede usarce se encuentran en las man page test (man test). Nosotros usaremos una simple condición para contar argumentos, pero pueden ser usadas distintas condiciones como nombres de archivos, permisos, si son o no directorios, etc.
Para saber si la cantidad de argumentos que se nos a pasado en el script es correcta, utilizaremos una opción aritmética que compare la cantidad de argumentos pasados ($#) con un numero que nosotros estipularemos, en este caso 3.
Pueden usarce diferentes opciones con el formato arg1 OP arg2, donde OP será alguno de los siguientes:-eq es igual
-ne no es igual
-lt menor que
-le menor que o igual
-gt mayor que
-ge mayor que o igualSe usará en este caso él "-ge" (mayor que o igual) dado que si la cantidad de argumentos que siguen al segundo es mayor la tomaremos como una frase a buscar y si es igual como una palabra. Lo único que haremos en caso de que la cantidad de argumentos sea menor, será informar de esto y de la forma de usar el script.
DIRECTORIO=$1
ARCHIVO_BUS=$2
shift 2
PALABRAS=$*if [ $# -ge 3 ]
then
ls $DIRECTORIO | grep $ARCHIVO_BUS | while read ARCHIVO
do
grep "$PALABRAS" ${DIRECTRIO}/${ARCHIVO}done
fi
else
echo "Numero de argumentos insuficientes"
echo "Use: $0 <directorio> <arvhivo_a_buscar> <palabras>"
fiOtra utilidad para del if, es la posibilidad de realizar lo que se denomina if anidados. De esta forma podríamos tener varias capas de if-then-else-fi.
Como ejemplo podría ser esta una construcción valida:if [ $condición1 = "true" ]
then
if [ $condición2 = "true" ]
then
if [ $condición3 = "true" ]
then
echo "las condiciones 1,2 y 3 son ciertas"
else
echo "solo son ciertas las condiciones 1 y 2 "
fi
else
echo "solo la condición 1 es cierta"
fi
else
echo "ninguna condición es cierta"
fiPodríamos también hacer que una sola variable tome diferente valores e interactuar con ella para ver si se cumple la condición buscada. De esta forma podríamos por ejemplo hacer un menú de usuario con distintas alternativas.
Pero esta forma es útil solo para pocas condiciones, pero que pasaría si tuviéramos muchas condiciones mas que agregar. Se nos haría por demás de complicado seguir el esquema armado y seria demasiado código para lo que se trata de realizar. Es aquí es donde se necesita algo como el case-esac.
Como se podrá ver , al igual que en el if y el fi aquí el inverso de case (esac) cierra la construcción.
Un ejemplo de una construcción con case seria:read elección
case $elección in
a) programa1;;
b) programa2;;
c) programa3;;
*) echo "No eligió ninguna opción valida";;
esacHay que tener en cuenta algunas cosas respecto a este tipo de construcción.
Por ejemplo el mandato que le damos al principio "read" indica al bash que tiene que leer lo que se ingrese a continuación y lo guarde en una variable que se llamara "elección".
Esto también será útil para el uso de otras construcciones ya que el read no es propiedad exclusiva de la construcción case-esca, sino que pertenece al mismo bash.
Como se ve, se le indica que di el valor que la variable contenga es igual a alguna de las mostradas debajo se ejecute determinado programa. (case $elección in)
La elección se debe terminar con un paréntesis ")" para que se cierre las posibilidades. Podríamos poner mas posibilidades para cada elección lo único que hay que recordar es cerrar con un paréntesis.
El punto y coma nos marca el final de un bloque, por lo que podríamos agregar otro comando y se cerrara con punto y coma doble al último.
El asterisco del final nos indica que se hará en caso de que no coincida lo ingresado con ninguna de las posibilidades.
Un ejemplo seria que nuestra construcción reconozca mayúsculas y minúsculas y además ejecute más de un comando por bloque.read elección
case $elección in
a|A) programa1
programa2
program3;;
b|B)
programa4
programa5;;c|C)
programa3;;*) echo "No eligió ninguna opción valida";;
esac
También se podría haber incluido un rango de posibilidades:
echo "Ingrese un carácter: "
read eleccion
case $eleccion in
[1-9]) echo "Usted ingreso un numero";;
[a-z]) echo "Usted ingreso una letra minúscula";;
[A-Z]) echo "Usted ingreso una letra mayúscula";;
esacHay que recordar que todos estos script podrán estar en un archivo, pero para que se ejecuten se le deberá primero dar los permisos pertinentes.
Un par de cosas a tener en cuenta para la construcción de script son la forma en que se quiere que ejecute este y la captura de teclas.Al ejecutarse un script de shell, se estará creando un bash hijo que lo ejecutara y dado que las variables y funciones pertenecen al interprete de comandos que las creo, al finalizar el script el proceso hijo del bash morirá y con el todos los seteos de variables y funciones.
Por esto, si se quisiera que los cambios de las variables y las funciones que se definieron permanecieran siendo utilizables una vez que el script haya terminado, se deberá comenzar a ejecutar el script con un punto "." seguido por un espacio antes del nombre de este. De esta forma el proceso del interprete de comando actual será quien ejecute el script con lo que se conservaran todas las variables y funciones.
Ej:. miscript
Un script puede dejar cosas sueltas antes de terminar si este es finalizado bruscamente enviándole una señal de finalización (para saber el nombre y numero de señales teclear kill -l) ya sea con la combinación de tecla ctrl.+C o con un kill -15.
Para esto se deberán capturar estas señales para poder hacer una limpieza, ya se de variables o archivos, antes de finalizar.
La forma de hacerlo es con el uso del comando "trap", de esta forma se capturara la señal que se le envíe al script y se podrá ya sea ignorar o ejecutar otro comando de limpieza.
Para demostrar esto haremos un pequeño script que servirá de menú. La llamada al script del menú podría estar en el archivo .profile del usuario o en el .bash_profile.
Si lo que no queremos es que el usuario salga del script con usando la combinación de teclas ctrl.+c, lo que haremos es capturar la señal y hacer que se ejecute nuevamente el script que se llamara simplemente "menú".trap './menu' 2
echo 'a) Listado de archivos'
echo 'b) Día y hora actual'
echo 'c) Mes actual'
echo 'Seleccione: '
read eleccion
case $eleccion in
a) ls;;
b) date;;
c) cal;;
*) echo "No eligió ninguna opción valida";;
esac
./menuComo se ve al principio del script se uso el comando "trap" que al captura la señal 2 (SIGINT) que produce el ctrl.+c relanza el script.
Al final del script se ve que se llama nuevamente dado que al ejecutarse el comando de cada elección se quiere que el menú siga estando.Practicar con estas construcciones será de gran ayuda para entender el proceso de construcción de script y los preparara para script más complejos usando otros interpretes como el "sed", "awk" y el lenguaje "perl".
Para mayor información respecto a la construcción de script, remitirse a las paginas de manual del interprete de comandos, en este caso "man bash".
Sebastian D. criado - seba_AT_lugro.org.ar
www.lugro.org.ar

